ワンソースマルチユースという考え方があります。情報加工に携わる者にとって魅力的な考え方ですが、実際にやってみるとなかなかうまく行きません。むしろ、不適切な結果しか得られなかったり、手間がかかりすぎたりするのがふつうです。こうした難点を低減する手法として、HTMLの利用が注目されています。今回はこれについて考えてみます。
ワンソースマルチユースとは、文字どおり一つの原稿(ワンソース)をさまざまな用途(マルチユース)に展開することです。とは言っても、1本の原稿からそれぞれ別の工程を経て、印刷物、電子書籍、Webページなどを作り出すのでは面白みがありません。たとえば、それぞれの工程の作業量を1として、全体で1+1+1=3の作業量になるところを1+1+1=2で片付けようというのがワンソースマルチユースの考え方です。たんにワンソースを使いまわすのではなく、いかに効率良く使いまわすかが眼目です。
ワンソースマルチユースの理念は良いとして、現実のメリットが得にくい最大の原因は、皮肉なことですが、それぞれの現場が得意とする技術にあります。たとえば印刷会社なら組版が得意です。そこで、いったん組版データとして組み上がったものをマルチユースの起点にしがちですが、デザイナーやDTPオペレーターのセンスとスキルによって高度に仕上げられた組版済みデータは、他の用途に振り向けるには不向きです。
同じことはWeb制作会社についてもいえます。Webページとしてていねいに作りこんだデータを他の用途に振り向けるには困難が伴います。
多くのデータ形式の中で、かなり無難に変換できるものとしては、組版データからPDFへの変換くらいしかありません。これはPDFが印刷物を表現するための言語PostScriptから発展した技術であることや、すでに多くの印刷現場でPDFが標準データとして扱われていることから見ても当然です。また、WebページからEPUB電子書籍への変換も、組版データからPDFへの変換ほどではないとしても、比較的容易です。これはWebとEPUBがともにHTMLを基本フォーマットとしていることによります。しかし、これらのケースを除けば、たいがいのフォーマット変換はスムーズには終わらず、マルチユースの理想に反して逆に手間が増えたりもします。
話を簡単にするために、一つの原稿という言い方をしましたが、一つのコンテンツを作成するために用意される素材(原稿)は、テキストのほかに、写真、イラスト、ロゴ、音声、映像など多岐にわたります。これらすべてを単一の目的(たとえば印刷物)のためにだけ加工して、さらに全体として作りこんだデータは、マルチユースのデータとしては不向きです。
まとめていうと、それぞれの現場で特定の技術やセンスを駆使して作り上げてしまうことが、マルチユースのネックとなります。特定の技術に熟達しているために、かえって袋小路に入ってしまう。これがワンソースマルチユースを実現させにくくする大きな原因です。
加工しすぎないこと――これがワンソースマルチユースの要点です。
これ以上加工すると他のフォーマットへの変換がやりにくくなるという段階で、いったん加工を中断し、その半製品を標準データとすると、効果的なワンソースマルチユースのフローを組むことができます。
半製品のデータ形式を何にするかはそれぞれ得失があります。汎用性の点では(マルチユースできるためには汎用性が欠かせません)、これまではXMLが有力な選択肢でしたが、最近はXMLに代わってHTMLを採用する動きが出てきています。
標準データの形式としてHTMLの地位が高まっている理由として、まず、XMLを扱える技術者よりHTML技術者のほうが圧倒的に多いことがあげられます(これについては「テレビ画面もHTMLで表示」でも触れました)。
また、HTMLの文法に従った正しいHTMLが容易に作れるようになったことがあります。Webが一般に広まりだした時期、多くのWeb制作者はいわゆる「手打ち」でHTMLを書いていました。そのため、誤入力やHTML文法の勝手な解釈も目立っていましたが、現在ではHTMLは自動生成するのがふつうです。自動生成ならば、そのための生成ソフトウェアさえ正しく作られていれば、結果として得られるHTMLの正しさは保証されます。それだけHTMLが安心して利用できるデータになってきているのです。
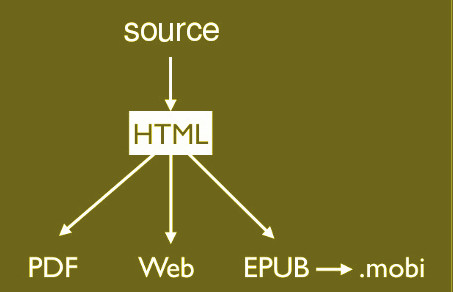
HTMLを標準データ(半製品データ)とするときの制作フローは次のようになります。
ところで「これ以上加工すると他のフォーマットへの変換がやりにくくなる段階」とはどのような段階をいうのでしょう。一般論としては、「デザイン情報を含めない」ということができます。半製品段階のHTMLでは、文書の構造だけを記述し、グラフィックデザインのための情報を盛り込まないことが肝要です。具体的には、見出しを作りこまない、文字の書体やサイズを指定しない(かわりに、「大見出し」、「小見出し」といった抽象的な指定をする)、回りこみなどメディアによってデザインの崩れるような配置を(この段階では)避ける、などです。
上図の中央にある「HTML」が、できるだけデザイン情報を排除したシンプルなHTMLであるとして、ここからは目的によって別々のフローになります。
このHTMLをWebページとして仕上げるには、CSSを適用すれば基本的な作業は終わりです。HTMLには文書構造を記し、デザイン情報はCSSに集約するという使い分けです。
EPUBへの変換も比較的容易です。この場合もデザイン情報はCSSで記述します。適切なHTMLとCSSさえ用意できれば、変換ツールにかけるだけでEPUB書籍となります。図に「.mobi」とあるのはAmazon Kindle用のデータ形式です。EPUBから.mobiへの変換には、Amazonが配布しているツールを利用します。これも操作は簡単です。
PDFへの加工は、印刷物を作るのとほぼ同じ意味です。シンプルな紙面のものならば、ツールを使って直接変換することも可能ですが、一般には半製品のHTMLを組版ソフトに読み込んで細部を仕上げるというフローになります。ただし、PDF(印刷物)についても、HTMLにCSSを適用するだけで済ます手法が試みられています。まだ可能性の段階ですが、Webだけでなく印刷を含むおおかたの出版物の生成がHTML+CSSに移行するという展開もありえます。
では、制作フローの要所に位置し、マルチユースの起点になるHTMLは、誰がどのように作ればいいのでしょう。次回は、誰でも簡単に半製品HTMLを作ることのできる手法を紹介します。
[2013-11-26]